Bayesian Logistic Regression
Bayesian logistic regression is the Bayesian counterpart to a common tool in machine learning, logistic regression. The goal of logistic regression is to predict a one or a zero for a given training item. An example might be predicting whether someone is sick or ill given their symptoms and personal information.
In our example, we'll be working to predict whether someone is likely to default with a synthetic dataset found in the RDatasets package. This dataset, Defaults, comes from R's ISLR package and contains information on borrowers.
To start, let's import all the libraries we'll need.
# Import Turing and Distributions.
using Turing, Distributions
# Import RDatasets.
using RDatasets
# Import MCMCChains, Plots, and StatsPlots for visualizations and diagnostics.
using MCMCChains, Plots, StatsPlots
# We need a logistic function, which is provided by StatsFuns.
using StatsFuns: logistic
# Functionality for splitting and normalizing the data
using MLDataUtils: shuffleobs, stratifiedobs, rescale!
# Set a seed for reproducibility.
using Random
Random.seed!(0);
# Turn off progress monitor.
Turing.setprogress!(false)
false
Data Cleaning & Set Up
Now we're going to import our dataset. The first six rows of the dataset are shown below so you can get a good feel for what kind of data we have.
# Import the "Default" dataset.
data = RDatasets.dataset("ISLR", "Default");
# Show the first six rows of the dataset.
first(data, 6)
6×4 DataFrame
Row │ Default Student Balance Income
│ Cat… Cat… Float64 Float64
─────┼──────────────────────────────────────
1 │ No No 729.526 44361.6
2 │ No Yes 817.18 12106.1
3 │ No No 1073.55 31767.1
4 │ No No 529.251 35704.5
5 │ No No 785.656 38463.5
6 │ No Yes 919.589 7491.56
Most machine learning processes require some effort to tidy up the data, and this is no different. We need to convert the Default and Student columns, which say "Yes" or "No" into 1s and 0s. Afterwards, we'll get rid of the old words-based columns.
# Convert "Default" and "Student" to numeric values.
data[!, :DefaultNum] = [r.Default == "Yes" ? 1.0 : 0.0 for r in eachrow(data)]
data[!, :StudentNum] = [r.Student == "Yes" ? 1.0 : 0.0 for r in eachrow(data)]
# Delete the old columns which say "Yes" and "No".
select!(data, Not([:Default, :Student]))
# Show the first six rows of our edited dataset.
first(data, 6)
6×4 DataFrame
Row │ Balance Income DefaultNum StudentNum
│ Float64 Float64 Float64 Float64
─────┼────────────────────────────────────────────
1 │ 729.526 44361.6 0.0 0.0
2 │ 817.18 12106.1 0.0 1.0
3 │ 1073.55 31767.1 0.0 0.0
4 │ 529.251 35704.5 0.0 0.0
5 │ 785.656 38463.5 0.0 0.0
6 │ 919.589 7491.56 0.0 1.0
After we've done that tidying, it's time to split our dataset into training and testing sets, and separate the labels from the data. We separate our data into two halves, train and test. You can use a higher percentage of splitting (or a lower one) by modifying the at = 0.05 argument. We have highlighted the use of only a 5% sample to show the power of Bayesian inference with small sample sizes.
We must rescale our variables so that they are centered around zero by subtracting each column by the mean and dividing it by the standard deviation. Without this step, Turing's sampler will have a hard time finding a place to start searching for parameter estimates. To do this we will leverage MLDataUtils, which also lets us effortlessly shuffle our observations and perform a stratified split to get a representative test set.
function split_data(df, target; at=0.70)
shuffled = shuffleobs(df)
return trainset, testset = stratifiedobs(row -> row[target], shuffled; p=at)
end
features = [:StudentNum, :Balance, :Income]
numerics = [:Balance, :Income]
target = :DefaultNum
trainset, testset = split_data(data, target; at=0.05)
for feature in numerics
μ, σ = rescale!(trainset[!, feature]; obsdim=1)
rescale!(testset[!, feature], μ, σ; obsdim=1)
end
# Turing requires data in matrix form, not dataframe
train = Matrix(trainset[:, features])
test = Matrix(testset[:, features])
train_label = trainset[:, target]
test_label = testset[:, target];
Model Declaration
Finally, we can define our model.
logistic_regression takes four arguments:
xis our set of independent variables;yis the element we want to predict;nis the number of observations we have; andσis the standard deviation we want to assume for our priors.
Within the model, we create four coefficients (intercept, student, balance, and income) and assign a prior of normally distributed with means of zero and standard deviations of σ. We want to find values of these four coefficients to predict any given y.
The for block creates a variable v which is the logistic function. We then observe the likelihood of calculating v given the actual label, y[i].
# Bayesian logistic regression (LR)
@model function logistic_regression(x, y, n, σ)
intercept ~ Normal(0, σ)
student ~ Normal(0, σ)
balance ~ Normal(0, σ)
income ~ Normal(0, σ)
for i in 1:n
v = logistic(intercept + student * x[i, 1] + balance * x[i, 2] + income * x[i, 3])
y[i] ~ Bernoulli(v)
end
end;
Sampling
Now we can run our sampler. This time we'll use HMC to sample from our posterior.
# Retrieve the number of observations.
n, _ = size(train)
# Sample using HMC.
m = logistic_regression(train, train_label, n, 1)
chain = sample(m, HMC(0.05, 10), MCMCThreads(), 1_500, 3)
Chains MCMC chain (1500×13×3 Array{Float64, 3}):
Iterations = 1:1:1500
Number of chains = 3
Samples per chain = 1500
Wall duration = 3.94 seconds
Compute duration = 3.32 seconds
parameters = income, student, intercept, balance
internals = lp, n_steps, is_accept, acceptance_rate, log_density, h
amiltonian_energy, hamiltonian_energy_error, step_size, nom_step_size
Summary Statistics
parameters mean std naive_se mcse ess rhat
⋯
Symbol Float64 Float64 Float64 Float64 Float64 Float64
⋯
intercept -3.8134 0.4469 0.0067 0.0120 1300.8182 1.0009
⋯
student -1.8813 0.6183 0.0092 0.0211 765.6952 1.0031
⋯
balance 1.6466 0.2938 0.0044 0.0071 1824.3353 1.0013
⋯
income -0.5267 0.3384 0.0050 0.0085 1645.2522 1.0004
⋯
1 column om
itted
Quantiles
parameters 2.5% 25.0% 50.0% 75.0% 97.5%
Symbol Float64 Float64 Float64 Float64 Float64
intercept -4.6138 -4.0549 -3.7916 -3.5396 -3.1080
student -3.0908 -2.2857 -1.8758 -1.4509 -0.6814
balance 1.1393 1.4685 1.6436 1.8165 2.1741
income -1.1955 -0.7445 -0.5200 -0.3011 0.1072
Since we ran multiple chains, we may as well do a spot check to make sure each chain converges around similar points.
plot(chain)
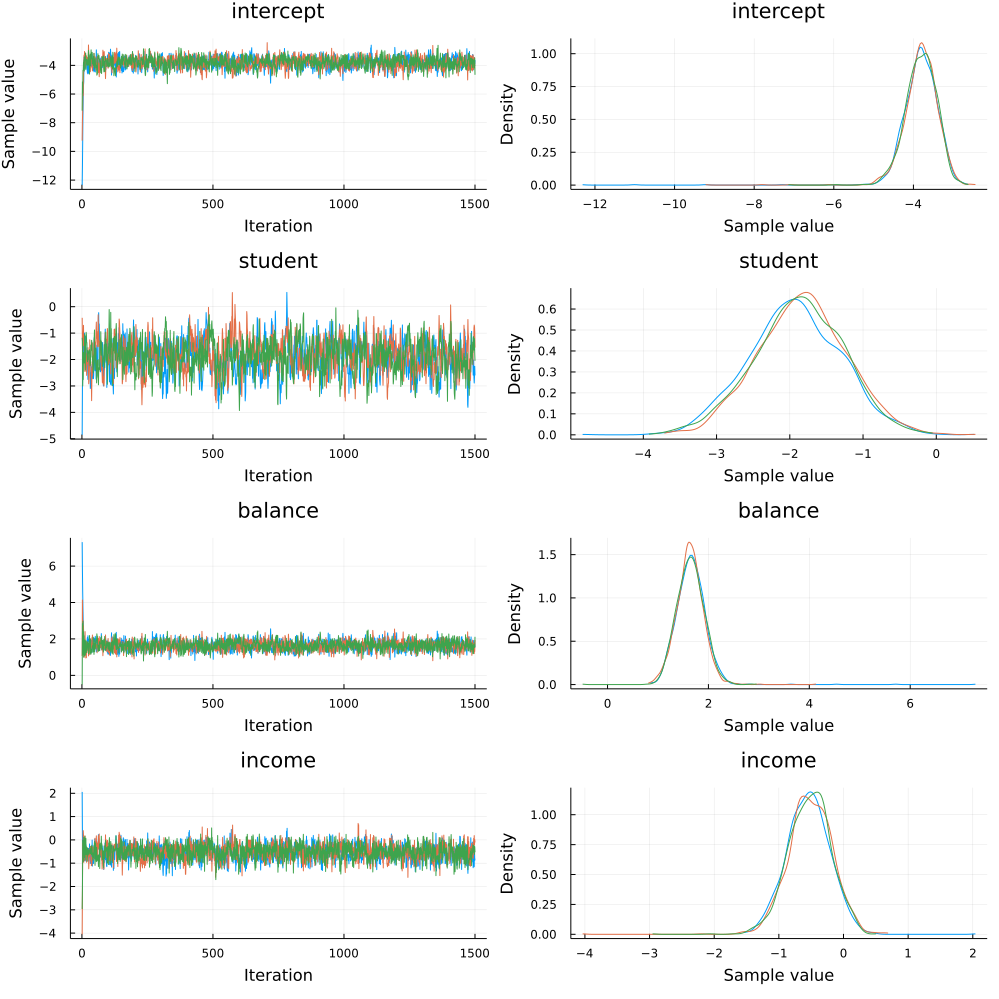
Looks good!
We can also use the corner function from MCMCChains to show the distributions of the various parameters of our logistic regression.
# The labels to use.
l = [:student, :balance, :income]
# Use the corner function. Requires StatsPlots and MCMCChains.
corner(chain, l)
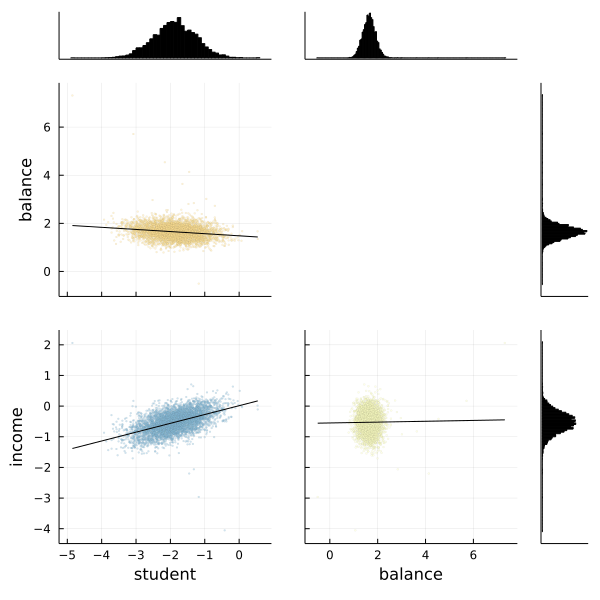
Fortunately the corner plot appears to demonstrate unimodal distributions for each of our parameters, so it should be straightforward to take the means of each parameter's sampled values to estimate our model to make predictions.
Making Predictions
How do we test how well the model actually predicts whether someone is likely to default? We need to build a prediction function that takes the test object we made earlier and runs it through the average parameter calculated during sampling.
The prediction function below takes a Matrix and a Chain object. It takes the mean of each parameter's sampled values and re-runs the logistic function using those mean values for every element in the test set.
function prediction(x::Matrix, chain, threshold)
# Pull the means from each parameter's sampled values in the chain.
intercept = mean(chain[:intercept])
student = mean(chain[:student])
balance = mean(chain[:balance])
income = mean(chain[:income])
# Retrieve the number of rows.
n, _ = size(x)
# Generate a vector to store our predictions.
v = Vector{Float64}(undef, n)
# Calculate the logistic function for each element in the test set.
for i in 1:n
num = logistic(
intercept .+ student * x[i, 1] + balance * x[i, 2] + income * x[i, 3]
)
if num >= threshold
v[i] = 1
else
v[i] = 0
end
end
return v
end;
Let's see how we did! We run the test matrix through the prediction function, and compute the mean squared error (MSE) for our prediction. The threshold variable sets the sensitivity of the predictions. For example, a threshold of 0.07 will predict a defualt value of 1 for any predicted value greater than 0.07 and no default if it is less than 0.07.
# Set the prediction threshold.
threshold = 0.07
# Make the predictions.
predictions = prediction(test, chain, threshold)
# Calculate MSE for our test set.
loss = sum((predictions - test_label) .^ 2) / length(test_label)
0.1171578947368421
Perhaps more important is to see what percentage of defaults we correctly predicted. The code below simply counts defaults and predictions and presents the results.
defaults = sum(test_label)
not_defaults = length(test_label) - defaults
predicted_defaults = sum(test_label .== predictions .== 1)
predicted_not_defaults = sum(test_label .== predictions .== 0)
println("Defaults: $defaults
Predictions: $predicted_defaults
Percentage defaults correct $(predicted_defaults/defaults)")
println("Not defaults: $not_defaults
Predictions: $predicted_not_defaults
Percentage non-defaults correct $(predicted_not_defaults/not_defaults)")
Defaults: 316.0
Predictions: 265
Percentage defaults correct 0.8386075949367089
Not defaults: 9184.0
Predictions: 8122
Percentage non-defaults correct 0.8843641114982579
The above shows that with a threshold of 0.07, we correctly predict a respectable portion of the defaults, and correctly identify most non-defaults. This is fairly sensitive to a choice of threshold, and you may wish to experiment with it.
This tutorial has demonstrated how to use Turing to perform Bayesian logistic regression.
Appendix
These tutorials are a part of the TuringTutorials repository, found at: https://github.com/TuringLang/TuringTutorials.
To locally run this tutorial, do the following commands:
using TuringTutorials
TuringTutorials.weave("02-logistic-regression", "02_logistic-regression.jmd")
Computer Information:
Julia Version 1.6.7
Commit 3b76b25b64 (2022-07-19 15:11 UTC)
Platform Info:
OS: Linux (x86_64-pc-linux-gnu)
CPU: AMD EPYC 7502 32-Core Processor
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-11.0.1 (ORCJIT, znver2)
Environment:
JULIA_CPU_THREADS = 128
BUILDKITE_PLUGIN_JULIA_CACHE_DIR = /cache/julia-buildkite-plugin
JULIA_DEPOT_PATH = /cache/julia-buildkite-plugin/depots/7aa0085e-79a4-45f3-a5bd-9743c91cf3da
Package Information:
Status `/cache/build/exclusive-amdci1-0/julialang/turingtutorials/tutorials/02-logistic-regression/Project.toml`
[a93c6f00] DataFrames v1.3.2
[b4f34e82] Distances v0.10.7
[31c24e10] Distributions v0.25.14
[5789e2e9] FileIO v1.13.0
[38e38edf] GLM v1.6.1
[c7f686f2] MCMCChains v4.14.1
[cc2ba9b6] MLDataUtils v0.5.4
[872c559c] NNlib v0.7.34
[91a5bcdd] Plots v1.25.5
[ce6b1742] RDatasets v0.7.7
[4c63d2b9] StatsFuns v0.9.9
[f3b207a7] StatsPlots v0.14.30
[fce5fe82] Turing v0.17.4
[9a3f8284] Random
And the full manifest:
Status `/cache/build/exclusive-amdci1-0/julialang/turingtutorials/tutorials/02-logistic-regression/Manifest.toml`
[621f4979] AbstractFFTs v1.0.1
[80f14c24] AbstractMCMC v3.2.1
[7a57a42e] AbstractPPL v0.2.0
[1520ce14] AbstractTrees v0.3.4
[79e6a3ab] Adapt v3.3.3
[0bf59076] AdvancedHMC v0.3.3
[5b7e9947] AdvancedMH v0.6.6
[576499cb] AdvancedPS v0.2.4
[b5ca4192] AdvancedVI v0.1.3
[dce04be8] ArgCheck v2.3.0
[7d9fca2a] Arpack v0.4.0
[4fba245c] ArrayInterface v4.0.3
[13072b0f] AxisAlgorithms v1.0.1
[39de3d68] AxisArrays v0.4.4
[198e06fe] BangBang v0.3.35
[9718e550] Baselet v0.1.1
[76274a88] Bijectors v0.9.7
[336ed68f] CSV v0.10.2
[324d7699] CategoricalArrays v0.10.2
[082447d4] ChainRules v0.8.25
[d360d2e6] ChainRulesCore v0.10.13
[aaaa29a8] Clustering v0.14.2
[944b1d66] CodecZlib v0.7.0
[35d6a980] ColorSchemes v3.17.1
[3da002f7] ColorTypes v0.11.0
[5ae59095] Colors v0.12.8
[861a8166] Combinatorics v1.0.2
[38540f10] CommonSolve v0.2.0
[bbf7d656] CommonSubexpressions v0.3.0
[34da2185] Compat v3.41.0
[a33af91c] CompositionsBase v0.1.1
[88cd18e8] ConsoleProgressMonitor v0.1.2
[187b0558] ConstructionBase v1.3.0
[d38c429a] Contour v0.5.7
[a8cc5b0e] Crayons v4.1.1
[9a962f9c] DataAPI v1.9.0
[a93c6f00] DataFrames v1.3.2
[864edb3b] DataStructures v0.18.11
[e2d170a0] DataValueInterfaces v1.0.0
[e7dc6d0d] DataValues v0.4.13
[244e2a9f] DefineSingletons v0.1.2
[163ba53b] DiffResults v1.0.3
[b552c78f] DiffRules v1.5.0
[b4f34e82] Distances v0.10.7
[31c24e10] Distributions v0.25.14
[ced4e74d] DistributionsAD v0.6.29
[ffbed154] DocStringExtensions v0.8.6
[366bfd00] DynamicPPL v0.14.1
[da5c29d0] EllipsisNotation v1.3.0
[cad2338a] EllipticalSliceSampling v0.4.6
[e2ba6199] ExprTools v0.1.8
[c87230d0] FFMPEG v0.4.1
[7a1cc6ca] FFTW v1.4.5
[5789e2e9] FileIO v1.13.0
[48062228] FilePathsBase v0.9.17
[1a297f60] FillArrays v0.11.9
[6a86dc24] FiniteDiff v2.10.1
[53c48c17] FixedPointNumbers v0.8.4
[59287772] Formatting v0.4.2
[f6369f11] ForwardDiff v0.10.25
[d9f16b24] Functors v0.2.8
[38e38edf] GLM v1.6.1
[28b8d3ca] GR v0.63.1
[5c1252a2] GeometryBasics v0.4.1
[42e2da0e] Grisu v1.0.2
[cd3eb016] HTTP v0.9.17
[615f187c] IfElse v0.1.1
[83e8ac13] IniFile v0.5.0
[22cec73e] InitialValues v0.3.1
[842dd82b] InlineStrings v1.1.2
[505f98c9] InplaceOps v0.3.0
[a98d9a8b] Interpolations v0.13.5
[8197267c] IntervalSets v0.5.3
[41ab1584] InvertedIndices v1.1.0
[92d709cd] IrrationalConstants v0.1.1
[c8e1da08] IterTools v1.4.0
[42fd0dbc] IterativeSolvers v0.9.2
[82899510] IteratorInterfaceExtensions v1.0.0
[692b3bcd] JLLWrappers v1.4.1
[682c06a0] JSON v0.21.3
[5ab0869b] KernelDensity v0.6.3
[b964fa9f] LaTeXStrings v1.3.0
[23fbe1c1] Latexify v0.15.11
[7f8f8fb0] LearnBase v0.3.0
[1d6d02ad] LeftChildRightSiblingTrees v0.1.3
[6f1fad26] Libtask v0.5.3
[2ab3a3ac] LogExpFunctions v0.3.0
[e6f89c97] LoggingExtras v0.4.7
[c7f686f2] MCMCChains v4.14.1
[9920b226] MLDataPattern v0.5.4
[cc2ba9b6] MLDataUtils v0.5.4
[e80e1ace] MLJModelInterface v1.3.6
[66a33bbf] MLLabelUtils v0.5.7
[1914dd2f] MacroTools v0.5.9
[dbb5928d] MappedArrays v0.4.1
[739be429] MbedTLS v1.0.3
[442fdcdd] Measures v0.3.1
[128add7d] MicroCollections v0.1.2
[e1d29d7a] Missings v1.0.2
[78c3b35d] Mocking v0.7.3
[6f286f6a] MultivariateStats v0.8.0
[872c559c] NNlib v0.7.34
[77ba4419] NaNMath v0.3.7
[86f7a689] NamedArrays v0.9.6
[c020b1a1] NaturalSort v1.0.0
[b8a86587] NearestNeighbors v0.4.9
[8913a72c] NonlinearSolve v0.3.14
[510215fc] Observables v0.4.0
[6fe1bfb0] OffsetArrays v1.10.8
[bac558e1] OrderedCollections v1.4.1
[90014a1f] PDMats v0.11.5
[69de0a69] Parsers v2.2.2
[ccf2f8ad] PlotThemes v2.0.1
[995b91a9] PlotUtils v1.1.3
[91a5bcdd] Plots v1.25.5
[2dfb63ee] PooledArrays v1.4.0
[21216c6a] Preferences v1.2.3
[08abe8d2] PrettyTables v1.3.1
[33c8b6b6] ProgressLogging v0.1.4
[92933f4c] ProgressMeter v1.7.1
[1fd47b50] QuadGK v2.4.2
[df47a6cb] RData v0.8.3
[ce6b1742] RDatasets v0.7.7
[b3c3ace0] RangeArrays v0.3.2
[c84ed2f1] Ratios v0.4.2
[3cdcf5f2] RecipesBase v1.2.1
[01d81517] RecipesPipeline v0.4.1
[731186ca] RecursiveArrayTools v2.24.2
[f2c3362d] RecursiveFactorization v0.1.0
[189a3867] Reexport v1.2.2
[05181044] RelocatableFolders v0.1.3
[ae029012] Requires v1.3.0
[79098fc4] Rmath v0.7.0
[0bca4576] SciMLBase v1.26.1
[30f210dd] ScientificTypesBase v3.0.0
[6c6a2e73] Scratch v1.1.0
[91c51154] SentinelArrays v1.3.12
[efcf1570] Setfield v0.8.2
[1277b4bf] ShiftedArrays v1.0.0
[992d4aef] Showoff v1.0.3
[a2af1166] SortingAlgorithms v1.0.1
[276daf66] SpecialFunctions v1.8.3
[171d559e] SplittablesBase v0.1.14
[aedffcd0] Static v0.5.5
[90137ffa] StaticArrays v1.3.5
[64bff920] StatisticalTraits v3.0.0
[82ae8749] StatsAPI v1.2.1
[2913bbd2] StatsBase v0.33.16
[4c63d2b9] StatsFuns v0.9.9
[3eaba693] StatsModels v0.6.28
[f3b207a7] StatsPlots v0.14.30
[09ab397b] StructArrays v0.6.5
[ab02a1b2] TableOperations v1.2.0
[3783bdb8] TableTraits v1.0.1
[bd369af6] Tables v1.6.1
[5d786b92] TerminalLoggers v0.1.5
[f269a46b] TimeZones v1.7.1
[9f7883ad] Tracker v0.2.19
[3bb67fe8] TranscodingStreams v0.9.6
[28d57a85] Transducers v0.4.72
[a2a6695c] TreeViews v0.3.0
[fce5fe82] Turing v0.17.4
[5c2747f8] URIs v1.3.0
[3a884ed6] UnPack v1.0.2
[1cfade01] UnicodeFun v0.4.1
[41fe7b60] Unzip v0.1.2
[ea10d353] WeakRefStrings v1.4.1
[cc8bc4a8] Widgets v0.6.5
[efce3f68] WoodburyMatrices v0.5.5
[700de1a5] ZygoteRules v0.2.2
[68821587] Arpack_jll v3.5.0+3
[6e34b625] Bzip2_jll v1.0.8+0
[83423d85] Cairo_jll v1.16.1+1
[5ae413db] EarCut_jll v2.2.3+0
[2e619515] Expat_jll v2.4.4+0
[b22a6f82] FFMPEG_jll v4.4.0+0
[f5851436] FFTW_jll v3.3.10+0
[a3f928ae] Fontconfig_jll v2.13.93+0
[d7e528f0] FreeType2_jll v2.10.4+0
[559328eb] FriBidi_jll v1.0.10+0
[0656b61e] GLFW_jll v3.3.6+0
[d2c73de3] GR_jll v0.64.0+0
[78b55507] Gettext_jll v0.21.0+0
[7746bdde] Glib_jll v2.68.3+2
[3b182d85] Graphite2_jll v1.3.14+0
[2e76f6c2] HarfBuzz_jll v2.8.1+1
[1d5cc7b8] IntelOpenMP_jll v2018.0.3+2
[aacddb02] JpegTurbo_jll v2.1.2+0
[c1c5ebd0] LAME_jll v3.100.1+0
[dd4b983a] LZO_jll v2.10.1+0
[e9f186c6] Libffi_jll v3.2.2+1
[d4300ac3] Libgcrypt_jll v1.8.7+0
[7e76a0d4] Libglvnd_jll v1.3.0+3
[7add5ba3] Libgpg_error_jll v1.42.0+0
[94ce4f54] Libiconv_jll v1.16.1+1
[4b2f31a3] Libmount_jll v2.35.0+0
[3ae2931a] Libtask_jll v0.4.3+0
[89763e89] Libtiff_jll v4.3.0+0
[38a345b3] Libuuid_jll v2.36.0+0
[856f044c] MKL_jll v2021.1.1+2
[e7412a2a] Ogg_jll v1.3.5+1
[458c3c95] OpenSSL_jll v1.1.13+0
[efe28fd5] OpenSpecFun_jll v0.5.5+0
[91d4177d] Opus_jll v1.3.2+0
[2f80f16e] PCRE_jll v8.44.0+0
[30392449] Pixman_jll v0.40.1+0
[ea2cea3b] Qt5Base_jll v5.15.3+0
[f50d1b31] Rmath_jll v0.3.0+0
[a2964d1f] Wayland_jll v1.19.0+0
[2381bf8a] Wayland_protocols_jll v1.23.0+0
[02c8fc9c] XML2_jll v2.9.12+0
[aed1982a] XSLT_jll v1.1.34+0
[4f6342f7] Xorg_libX11_jll v1.6.9+4
[0c0b7dd1] Xorg_libXau_jll v1.0.9+4
[935fb764] Xorg_libXcursor_jll v1.2.0+4
[a3789734] Xorg_libXdmcp_jll v1.1.3+4
[1082639a] Xorg_libXext_jll v1.3.4+4
[d091e8ba] Xorg_libXfixes_jll v5.0.3+4
[a51aa0fd] Xorg_libXi_jll v1.7.10+4
[d1454406] Xorg_libXinerama_jll v1.1.4+4
[ec84b674] Xorg_libXrandr_jll v1.5.2+4
[ea2f1a96] Xorg_libXrender_jll v0.9.10+4
[14d82f49] Xorg_libpthread_stubs_jll v0.1.0+3
[c7cfdc94] Xorg_libxcb_jll v1.13.0+3
[cc61e674] Xorg_libxkbfile_jll v1.1.0+4
[12413925] Xorg_xcb_util_image_jll v0.4.0+1
[2def613f] Xorg_xcb_util_jll v0.4.0+1
[975044d2] Xorg_xcb_util_keysyms_jll v0.4.0+1
[0d47668e] Xorg_xcb_util_renderutil_jll v0.3.9+1
[c22f9ab0] Xorg_xcb_util_wm_jll v0.4.1+1
[35661453] Xorg_xkbcomp_jll v1.4.2+4
[33bec58e] Xorg_xkeyboard_config_jll v2.27.0+4
[c5fb5394] Xorg_xtrans_jll v1.4.0+3
[3161d3a3] Zstd_jll v1.5.2+0
[0ac62f75] libass_jll v0.15.1+0
[f638f0a6] libfdk_aac_jll v2.0.2+0
[b53b4c65] libpng_jll v1.6.38+0
[f27f6e37] libvorbis_jll v1.3.7+1
[1270edf5] x264_jll v2021.5.5+0
[dfaa095f] x265_jll v3.5.0+0
[d8fb68d0] xkbcommon_jll v0.9.1+5
[0dad84c5] ArgTools
[56f22d72] Artifacts
[2a0f44e3] Base64
[ade2ca70] Dates
[8bb1440f] DelimitedFiles
[8ba89e20] Distributed
[f43a241f] Downloads
[9fa8497b] Future
[b77e0a4c] InteractiveUtils
[4af54fe1] LazyArtifacts
[b27032c2] LibCURL
[76f85450] LibGit2
[8f399da3] Libdl
[37e2e46d] LinearAlgebra
[56ddb016] Logging
[d6f4376e] Markdown
[a63ad114] Mmap
[ca575930] NetworkOptions
[44cfe95a] Pkg
[de0858da] Printf
[3fa0cd96] REPL
[9a3f8284] Random
[ea8e919c] SHA
[9e88b42a] Serialization
[1a1011a3] SharedArrays
[6462fe0b] Sockets
[2f01184e] SparseArrays
[10745b16] Statistics
[4607b0f0] SuiteSparse
[fa267f1f] TOML
[a4e569a6] Tar
[8dfed614] Test
[cf7118a7] UUIDs
[4ec0a83e] Unicode
[e66e0078] CompilerSupportLibraries_jll
[deac9b47] LibCURL_jll
[29816b5a] LibSSH2_jll
[c8ffd9c3] MbedTLS_jll
[14a3606d] MozillaCACerts_jll
[4536629a] OpenBLAS_jll
[05823500] OpenLibm_jll
[83775a58] Zlib_jll
[8e850ede] nghttp2_jll
[3f19e933] p7zip_jll