Bayesian Estimation of Differential Equations
Most of the scientific community deals with the basic problem of trying to mathematically model the reality around them and this often involves dynamical systems. The general trend to model these complex dynamical systems is through the use of differential equations. Differential equation models often have non-measurable parameters. The popular “forward-problem” of simulation consists of solving the differential equations for a given set of parameters, the “inverse problem” to simulation, known as parameter estimation, is the process of utilizing data to determine these model parameters. Bayesian inference provides a robust approach to parameter estimation with quantified uncertainty.
using Turing
using DifferentialEquations
# Load StatsPlots for visualizations and diagnostics.
using StatsPlots
using LinearAlgebra
# Set a seed for reproducibility.
using Random
Random.seed!(14);
The Lotka-Volterra Model
The Lotka–Volterra equations, also known as the predator–prey equations, are a pair of first-order nonlinear differential equations. These differential equations are frequently used to describe the dynamics of biological systems in which two species interact, one as a predator and the other as prey. The populations change through time according to the pair of equations
$$ \begin{aligned} \frac{\mathrm{d}x}{\mathrm{d}t} &= (\alpha - \beta y(t))x(t), \ \frac{\mathrm{d}y}{\mathrm{d}t} &= (\delta x(t) - \gamma)y(t) \end{aligned} $$
where $x(t)$ and $y(t)$ denote the populations of prey and predator at time $t$, respectively, and $\alpha, \beta, \gamma, \delta$ are positive parameters.
We implement the Lotka-Volterra model and simulate it with parameters $\alpha = 1.5$, $\beta = 1$, $\gamma = 3$, and $\delta = 1$ and initial conditions $x(0) = y(0) = 1$.
# Define Lotka-Volterra model.
function lotka_volterra(du, u, p, t)
# Model parameters.
α, β, γ, δ = p
# Current state.
x, y = u
# Evaluate differential equations.
du[1] = (α - β * y) * x # prey
du[2] = (δ * x - γ) * y # predator
return nothing
end
# Define initial-value problem.
u0 = [1.0, 1.0]
p = [1.5, 1.0, 3.0, 1.0]
tspan = (0.0, 10.0)
prob = ODEProblem(lotka_volterra, u0, tspan, p)
# Plot simulation.
plot(solve(prob, Tsit5()))
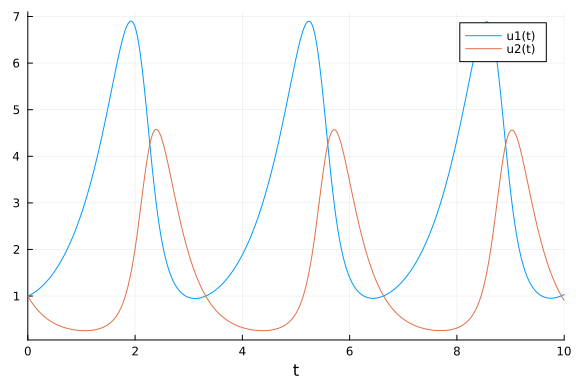
We generate noisy observations to use for the parameter estimation tasks in this tutorial.
With the saveat argument we specify that the solution is stored only at 0.1 time units.
To make the example more realistic we add random normally distributed noise to the simulation.
sol = solve(prob, Tsit5(); saveat=0.1)
odedata = Array(sol) + 0.8 * randn(size(Array(sol)))
# Plot simulation and noisy observations.
plot(sol; alpha=0.3)
scatter!(sol.t, odedata'; color=[1 2], label="")
Direct Handling of Bayesian Estimation with Turing
Previously, functions in Turing and DifferentialEquations were not inter-composable, so Bayesian inference of differential equations needed to be handled by another package called DiffEqBayes.jl (note that DiffEqBayes works also with CmdStan.jl, Turing.jl, DynamicHMC.jl and ApproxBayes.jl - see the DiffEqBayes docs for more info).
Nowadays, however, Turing and DifferentialEquations are completely composable and we can just simulate differential equations inside a Turing @model.
Therefore, we write the Lotka-Volterra parameter estimation problem using the Turing @model macro as below:
@model function fitlv(data, prob)
# Prior distributions.
σ ~ InverseGamma(2, 3)
α ~ truncated(Normal(1.5, 0.5); lower=0.5, upper=2.5)
β ~ truncated(Normal(1.2, 0.5); lower=0, upper=2)
γ ~ truncated(Normal(3.0, 0.5); lower=1, upper=4)
δ ~ truncated(Normal(1.0, 0.5); lower=0, upper=2)
# Simulate Lotka-Volterra model.
p = [α, β, γ, δ]
predicted = solve(prob, Tsit5(); p=p, saveat=0.1)
# Observations.
for i in 1:length(predicted)
data[:, i] ~ MvNormal(predicted[i], σ^2 * I)
end
return nothing
end
model = fitlv(odedata, prob)
# Sample 3 independent chains with forward-mode automatic differentiation (the default).
chain = sample(model, NUTS(0.65), MCMCSerial(), 1000, 3; progress=false)
Chains MCMC chain (1000×17×3 Array{Float64, 3}):
Iterations = 501:1:1500
Number of chains = 3
Samples per chain = 1000
Wall duration = 65.43 seconds
Compute duration = 64.95 seconds
parameters = σ, α, β, γ, δ
internals = lp, n_steps, is_accept, acceptance_rate, log_density, h
amiltonian_energy, hamiltonian_energy_error, max_hamiltonian_energy_error,
tree_depth, numerical_error, step_size, nom_step_size
Summary Statistics
parameters mean std naive_se mcse ess rhat
⋯
Symbol Float64 Float64 Float64 Float64 Float64 Float64
⋯
σ 0.8120 0.0411 0.0008 0.0011 1721.7324 1.0008
⋯
α 1.5540 0.0538 0.0010 0.0020 792.3794 1.0012
⋯
β 1.0903 0.0534 0.0010 0.0018 913.9769 1.0013
⋯
γ 2.8852 0.1426 0.0026 0.0053 815.5472 1.0010
⋯
δ 0.9404 0.0506 0.0009 0.0019 804.6753 1.0011
⋯
1 column om
itted
Quantiles
parameters 2.5% 25.0% 50.0% 75.0% 97.5%
Symbol Float64 Float64 Float64 Float64 Float64
σ 0.7342 0.7853 0.8099 0.8380 0.8962
α 1.4551 1.5168 1.5509 1.5888 1.6645
β 0.9930 1.0532 1.0881 1.1247 1.2030
γ 2.6111 2.7872 2.8859 2.9821 3.1675
δ 0.8422 0.9053 0.9405 0.9736 1.0395
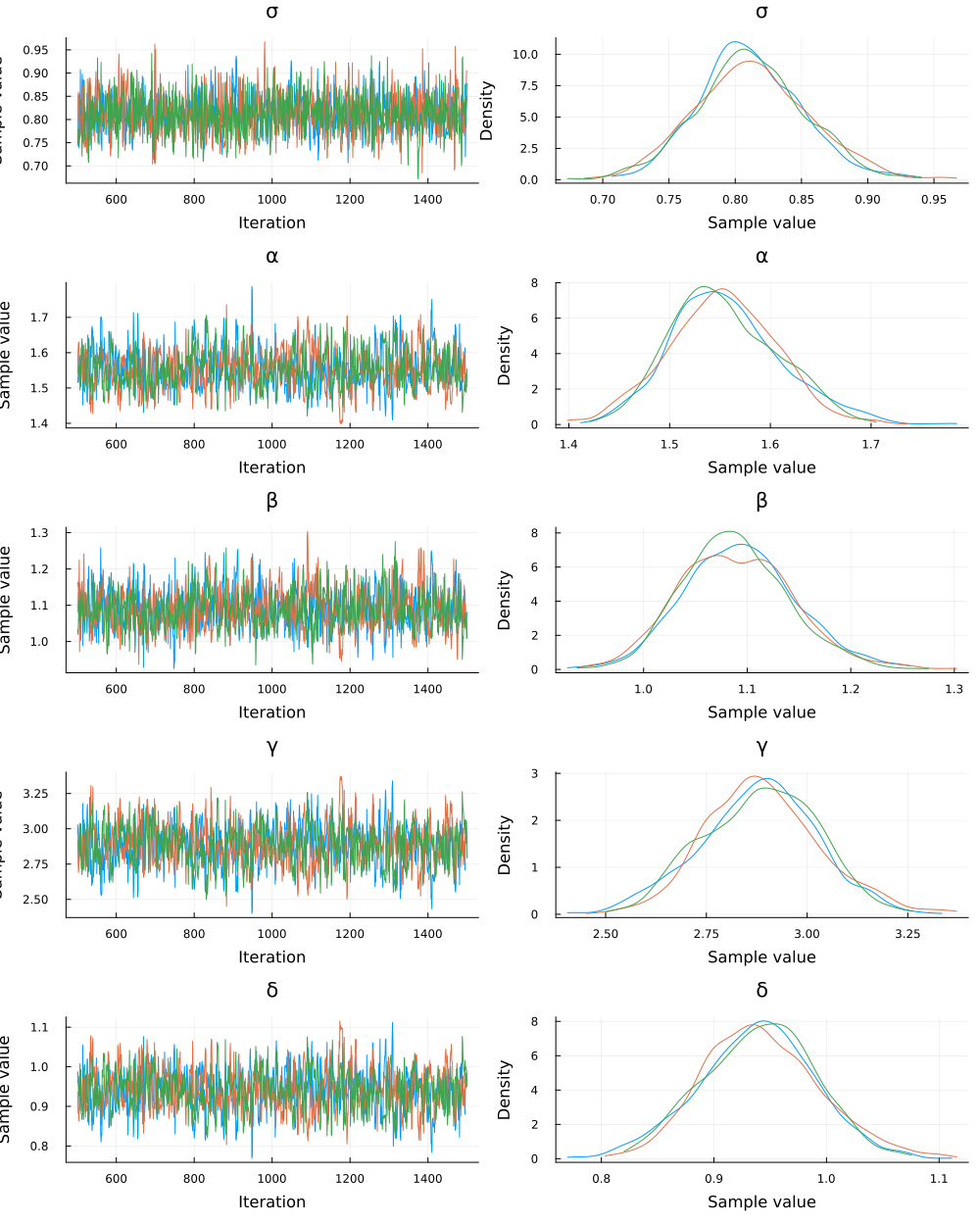
The estimated parameters are close to the parameter values the observations were generated with. We can also check visually that the chains have converged.
plot(chain)
Data retrodiction
In Bayesian analysis it is often useful to retrodict the data, i.e. generate simulated data using samples from the posterior distribution, and compare to the original data (see for instance section 3.3.2 - model checking of McElreath's book "Statistical Rethinking").
Here, we solve the ODE for 300 randomly picked posterior samples in the chain.
We plot the ensemble of solutions to check if the solution resembles the data.
The 300 retrodicted time courses from the posterior are plotted in gray, the noisy observations are shown as blue and red dots, and the green and purple lines are the ODE solution that was used to generate the data.
plot(; legend=false)
posterior_samples = sample(chain[[:α, :β, :γ, :δ]], 300; replace=false)
for p in eachrow(Array(posterior_samples))
sol_p = solve(prob, Tsit5(); p=p, saveat=0.1)
plot!(sol_p; alpha=0.1, color="#BBBBBB")
end
# Plot simulation and noisy observations.
plot!(sol; color=[1 2], linewidth=1)
scatter!(sol.t, odedata'; color=[1 2])
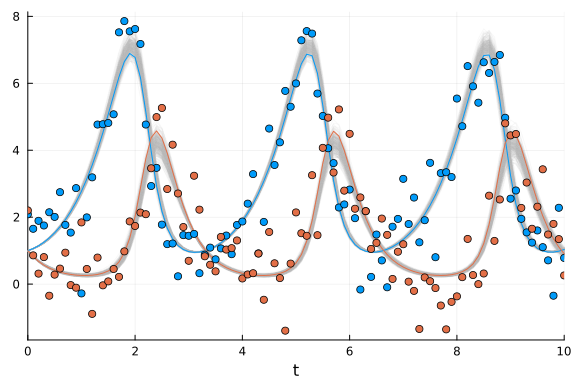
We can see that, even though we added quite a bit of noise to the data the posterior distribution reproduces quite accurately the "true" ODE solution.
Lotka-Volterra model without data of prey
One can also perform parameter inference for a Lotka-Volterra model with incomplete data. For instance, let us suppose we have only observations of the predators but not of the prey. I.e., we fit the model only to the $y$ variable of the system without providing any data for $x$:
@model function fitlv2(data::AbstractVector, prob)
# Prior distributions.
σ ~ InverseGamma(2, 3)
α ~ truncated(Normal(1.5, 0.5); lower=0.5, upper=2.5)
β ~ truncated(Normal(1.2, 0.5); lower=0, upper=2)
γ ~ truncated(Normal(3.0, 0.5); lower=1, upper=4)
δ ~ truncated(Normal(1.0, 0.5); lower=0, upper=2)
# Simulate Lotka-Volterra model but save only the second state of the system (predators).
p = [α, β, γ, δ]
predicted = solve(prob, Tsit5(); p=p, saveat=0.1, save_idxs=2)
# Observations of the predators.
data ~ MvNormal(predicted.u, σ^2 * I)
return nothing
end
model2 = fitlv2(odedata[2, :], prob)
# Sample 3 independent chains.
chain2 = sample(model2, NUTS(0.45), MCMCSerial(), 5000, 3; progress=false)
Chains MCMC chain (5000×17×3 Array{Float64, 3}):
Iterations = 1001:1:6000
Number of chains = 3
Samples per chain = 5000
Wall duration = 69.96 seconds
Compute duration = 69.4 seconds
parameters = σ, α, β, γ, δ
internals = lp, n_steps, is_accept, acceptance_rate, log_density, h
amiltonian_energy, hamiltonian_energy_error, max_hamiltonian_energy_error,
tree_depth, numerical_error, step_size, nom_step_size
Summary Statistics
parameters mean std naive_se mcse ess rhat
e ⋯
Symbol Float64 Float64 Float64 Float64 Float64 Float64
⋯
σ 0.8228 0.0582 0.0005 0.0033 170.0700 1.0351
⋯
α 1.5517 0.1840 0.0015 0.0091 305.3414 1.0084
⋯
β 1.1143 0.1492 0.0012 0.0072 323.7839 1.0075
⋯
γ 2.9782 0.2999 0.0024 0.0149 289.3999 1.0116
⋯
δ 0.9639 0.2504 0.0020 0.0123 296.9284 1.0092
⋯
1 column om
itted
Quantiles
parameters 2.5% 25.0% 50.0% 75.0% 97.5%
Symbol Float64 Float64 Float64 Float64 Float64
σ 0.7205 0.7824 0.8183 0.8598 0.9509
α 1.2373 1.4241 1.5384 1.6665 1.9604
β 0.8611 1.0078 1.1003 1.2120 1.4427
γ 2.4140 2.7778 2.9628 3.1706 3.5998
δ 0.5245 0.7828 0.9457 1.1211 1.4948
Again we inspect the trajectories of 300 randomly selected posterior samples.
plot(; legend=false)
posterior_samples = sample(chain2[[:α, :β, :γ, :δ]], 300; replace=false)
for p in eachrow(Array(posterior_samples))
sol_p = solve(prob, Tsit5(); p=p, saveat=0.1)
plot!(sol_p; alpha=0.1, color="#BBBBBB")
end
# Plot simulation and noisy observations.
plot!(sol; color=[1 2], linewidth=1)
scatter!(sol.t, odedata'; color=[1 2])
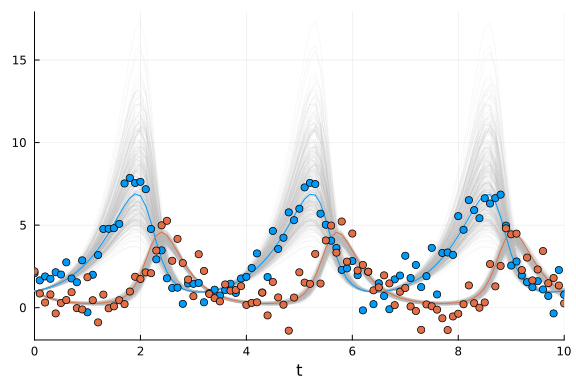
Note that here the observations of the prey (blue dots) were not used in the parameter estimation! Yet, the model can predict the values of $x$ relatively accurately, albeit with a wider distribution of solutions, reflecting the greater uncertainty in the prediction of the $x$ values.
Inference of Delay Differential Equations
Here we show an example of inference with another type of differential equation: a Delay Differential Equation (DDE). DDEs are differential equations where derivatives are function of values at an earlier point in time. This is useful to model a delayed effect, like incubation time of a virus for instance.
Here is a delayed version of the Lokta-Voltera system:
$$ \begin{aligned} \frac{\mathrm{d}x}{\mathrm{d}t} &= \alpha x(t-\tau) - \beta y(t) x(t),\ \frac{\mathrm{d}y}{\mathrm{d}t} &= - \gamma y(t) + \delta x(t) y(t), \end{aligned} $$
where $\tau$ is a (positive) delay and $x(t-\tau)$ is the variable $x$ at an earlier time point $t - \tau$.
The initial-value problem of the delayed system can be implemented as a DDEProblem.
As described in the DDE example, here the function h is the history function that can be used to obtain a state at an earlier time point.
Again we use parameters $\alpha = 1.5$, $\beta = 1$, $\gamma = 3$, and $\delta = 1$ and initial conditions $x(0) = y(0) = 1$.
Moreover, we assume $x(t) = 1$ for $t < 0$.
function delay_lotka_volterra(du, u, h, p, t)
# Model parameters.
α, β, γ, δ = p
# Current state.
x, y = u
# Evaluate differential equations
du[1] = α * h(p, t - 1; idxs=1) - β * x * y
du[2] = -γ * y + δ * x * y
return nothing
end
# Define initial-value problem.
p = (1.5, 1.0, 3.0, 1.0)
u0 = [1.0; 1.0]
tspan = (0.0, 10.0)
h(p, t; idxs::Int) = 1.0
prob_dde = DDEProblem(delay_lotka_volterra, u0, h, tspan, p);
We generate observations by adding normally distributed noise to the results of our simulations.
sol_dde = solve(prob_dde; saveat=0.1)
ddedata = Array(sol_dde) + 0.5 * randn(size(sol_dde))
# Plot simulation and noisy observations.
plot(sol_dde)
scatter!(sol_dde.t, ddedata'; color=[1 2], label="")
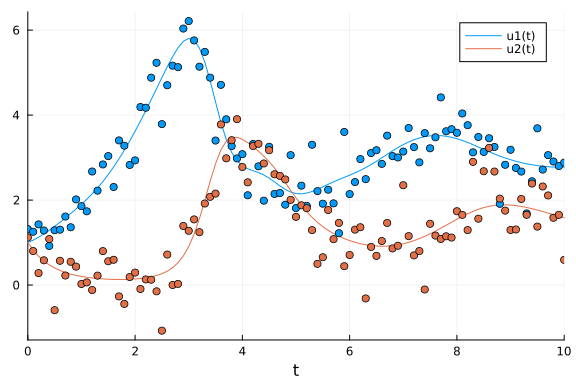
Now we define the Turing model for the Lotka-Volterra model with delay and sample 3 independent chains.
@model function fitlv_dde(data, prob)
# Prior distributions.
σ ~ InverseGamma(2, 3)
α ~ truncated(Normal(1.5, 0.5); lower=0.5, upper=2.5)
β ~ truncated(Normal(1.2, 0.5); lower=0, upper=2)
γ ~ truncated(Normal(3.0, 0.5); lower=1, upper=4)
δ ~ truncated(Normal(1.0, 0.5); lower=0, upper=2)
# Simulate Lotka-Volterra model.
p = [α, β, γ, δ]
predicted = solve(prob, MethodOfSteps(Tsit5()); p=p, saveat=0.1)
# Observations.
for i in 1:length(predicted)
data[:, i] ~ MvNormal(predicted[i], σ^2 * I)
end
end
model_dde = fitlv_dde(ddedata, prob_dde)
# Sample 3 independent chains.
chain_dde = sample(model_dde, NUTS(0.65), MCMCSerial(), 300, 3; progress=false)
Chains MCMC chain (300×17×3 Array{Float64, 3}):
Iterations = 151:1:450
Number of chains = 3
Samples per chain = 300
Wall duration = 22.98 seconds
Compute duration = 22.51 seconds
parameters = σ, α, β, γ, δ
internals = lp, n_steps, is_accept, acceptance_rate, log_density, h
amiltonian_energy, hamiltonian_energy_error, max_hamiltonian_energy_error,
tree_depth, numerical_error, step_size, nom_step_size
Summary Statistics
parameters mean std naive_se mcse ess rhat
e ⋯
Symbol Float64 Float64 Float64 Float64 Float64 Float64
⋯
σ 0.4949 0.0247 0.0008 0.0011 429.9468 0.9994
⋯
α 1.4868 0.0655 0.0022 0.0045 221.5918 1.0188
⋯
β 1.0235 0.0553 0.0018 0.0035 275.4992 1.0117
⋯
γ 3.0378 0.1382 0.0046 0.0099 216.0740 1.0301
⋯
δ 1.0152 0.0489 0.0016 0.0035 206.9970 1.0289
⋯
1 column om
itted
Quantiles
parameters 2.5% 25.0% 50.0% 75.0% 97.5%
Symbol Float64 Float64 Float64 Float64 Float64
σ 0.4482 0.4779 0.4936 0.5114 0.5480
α 1.3698 1.4463 1.4840 1.5212 1.6263
β 0.9245 0.9907 1.0197 1.0546 1.1358
γ 2.7761 2.9517 3.0302 3.1216 3.3129
δ 0.9237 0.9846 1.0137 1.0465 1.1145
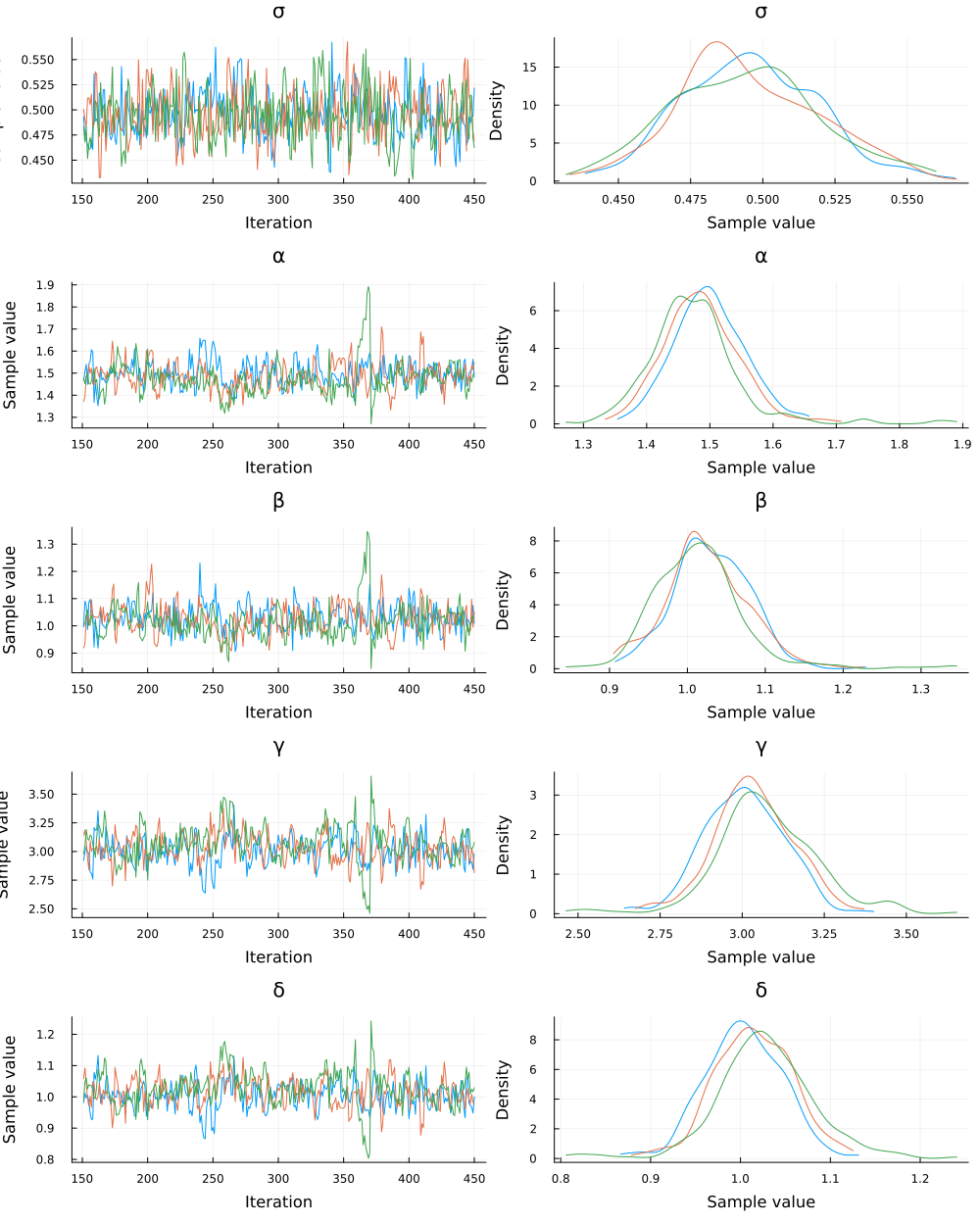
plot(chain_dde)
Finally, plot trajectories of 300 randomly selected samples from the posterior. Again, the dots indicate our observations, the colored lines are the "true" simulations without noise, and the gray lines are trajectories from the posterior samples.
plot(; legend=false)
posterior_samples = sample(chain_dde[[:α, :β, :γ, :δ]], 300; replace=false)
for p in eachrow(Array(posterior_samples))
sol_p = solve(prob_dde, MethodOfSteps(Tsit5()); p=p, saveat=0.1)
plot!(sol_p; alpha=0.1, color="#BBBBBB")
end
# Plot simulation and noisy observations.
plot!(sol_dde; color=[1 2], linewidth=1)
scatter!(sol_dde.t, ddedata'; color=[1 2])
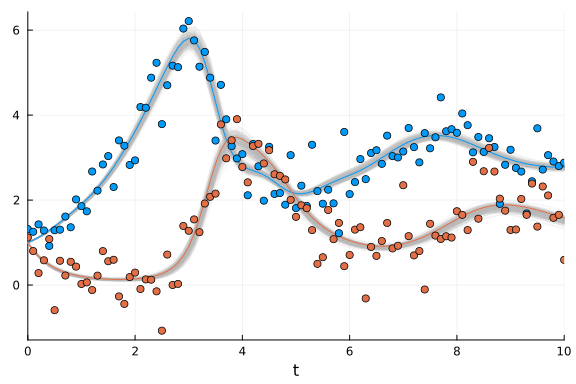
The fit is pretty good even though the data was quite noisy to start.
Scaling to Large Models: Adjoint Sensitivities
DifferentialEquations.jl's efficiency for large stiff models has been shown in multiple benchmarks. To learn more about how to optimize solving performance for stiff problems you can take a look at the docs.
Sensitivity analysis, or automatic differentiation (AD) of the solver, is provided by the DiffEq suite. The model sensitivities are the derivatives of the solution with respect to the parameters. Specifically, the local sensitivity of the solution to a parameter is defined by how much the solution would change by changes in the parameter. Sensitivity analysis provides a cheap way to calculate the gradient of the solution which can be used in parameter estimation and other optimization tasks.
The AD ecosystem in Julia allows you to switch between forward mode, reverse mode, source to source and other choices of AD and have it work with any Julia code.
For a user to make use of this within SciML, high level interactions in solve automatically plug into those AD systems to allow for choosing advanced sensitivity analysis (derivative calculation) methods.
More theoretical details on these methods can be found at: https://docs.sciml.ai/latest/extras/sensitivity_math/.
While these sensitivity analysis methods may seem complicated, using them is dead simple. Here is a version of the Lotka-Volterra model using adjoint sensitivities.
All we have to do is switch the AD backend to one of the adjoint-compatible backends (ReverseDiff, Tracker, or Zygote)! Notice that on this model adjoints are slower. This is because adjoints have a higher overhead on small parameter models and therefore we suggest using these methods only for models with around 100 parameters or more. For more details, see https://arxiv.org/abs/1812.01892.
using Zygote, SciMLSensitivity
# Sample a single chain with 1000 samples using Zygote.
setadbackend(:zygote)
sample(model, NUTS(0.65), 1000; progress=false)
Chains MCMC chain (1000×17×1 Array{Float64, 3}):
Iterations = 501:1:1500
Number of chains = 1
Samples per chain = 1000
Wall duration = 905.52 seconds
Compute duration = 905.52 seconds
parameters = σ, α, β, γ, δ
internals = lp, n_steps, is_accept, acceptance_rate, log_density, h
amiltonian_energy, hamiltonian_energy_error, max_hamiltonian_energy_error,
tree_depth, numerical_error, step_size, nom_step_size
Summary Statistics
parameters mean std naive_se mcse ess rhat
e ⋯
Symbol Float64 Float64 Float64 Float64 Float64 Float64
⋯
σ 0.8132 0.0403 0.0013 0.0015 519.2956 1.0067
⋯
α 1.5616 0.0531 0.0017 0.0039 183.9805 0.9992
⋯
β 1.0960 0.0519 0.0016 0.0032 247.6342 1.0013
⋯
γ 2.8648 0.1391 0.0044 0.0102 186.8802 0.9993
⋯
δ 0.9333 0.0499 0.0016 0.0037 186.9087 0.9990
⋯
1 column om
itted
Quantiles
parameters 2.5% 25.0% 50.0% 75.0% 97.5%
Symbol Float64 Float64 Float64 Float64 Float64
σ 0.7353 0.7861 0.8131 0.8401 0.8916
α 1.4662 1.5251 1.5586 1.5957 1.6633
β 1.0047 1.0599 1.0942 1.1281 1.2051
γ 2.6095 2.7725 2.8612 2.9594 3.1293
δ 0.8425 0.8989 0.9325 0.9659 1.0297
If desired, we can control the sensitivity analysis method that is used by providing the sensealg keyword argument to solve.
Here we will not choose a sensealg and let it use the default choice:
@model function fitlv_sensealg(data, prob)
# Prior distributions.
σ ~ InverseGamma(2, 3)
α ~ truncated(Normal(1.5, 0.5); lower=0.5, upper=2.5)
β ~ truncated(Normal(1.2, 0.5); lower=0, upper=2)
γ ~ truncated(Normal(3.0, 0.5); lower=1, upper=4)
δ ~ truncated(Normal(1.0, 0.5); lower=0, upper=2)
# Simulate Lotka-Volterra model and use a specific algorithm for computing sensitivities.
p = [α, β, γ, δ]
predicted = solve(prob; p=p, saveat=0.1)
# Observations.
for i in 1:length(predicted)
data[:, i] ~ MvNormal(predicted[i], σ^2 * I)
end
return nothing
end;
model_sensealg = fitlv_sensealg(odedata, prob)
# Sample a single chain with 1000 samples using Zygote.
setadbackend(:zygote)
sample(model_sensealg, NUTS(0.65), 1000; progress=false)
Chains MCMC chain (1000×17×1 Array{Float64, 3}):
Iterations = 501:1:1500
Number of chains = 1
Samples per chain = 1000
Wall duration = 1072.84 seconds
Compute duration = 1072.84 seconds
parameters = σ, α, β, γ, δ
internals = lp, n_steps, is_accept, acceptance_rate, log_density, h
amiltonian_energy, hamiltonian_energy_error, max_hamiltonian_energy_error,
tree_depth, numerical_error, step_size, nom_step_size
Summary Statistics
parameters mean std naive_se mcse ess rhat
e ⋯
Symbol Float64 Float64 Float64 Float64 Float64 Float64
⋯
σ 0.8128 0.0394 0.0012 0.0019 472.6523 1.0003
⋯
α 1.5577 0.0503 0.0016 0.0028 355.8089 1.0037
⋯
β 1.0930 0.0546 0.0017 0.0026 409.6718 1.0074
⋯
γ 2.8746 0.1325 0.0042 0.0070 367.8213 1.0024
⋯
δ 0.9364 0.0471 0.0015 0.0026 372.1754 1.0034
⋯
1 column om
itted
Quantiles
parameters 2.5% 25.0% 50.0% 75.0% 97.5%
Symbol Float64 Float64 Float64 Float64 Float64
σ 0.7410 0.7838 0.8107 0.8403 0.8923
α 1.4665 1.5229 1.5535 1.5918 1.6583
β 0.9970 1.0549 1.0894 1.1276 1.2053
γ 2.6226 2.7832 2.8771 2.9618 3.1311
δ 0.8442 0.9020 0.9379 0.9679 1.0293
For more examples of adjoint usage on large parameter models, consult the DiffEqFlux documentation.
Inference of a Stochastic Differential Equation
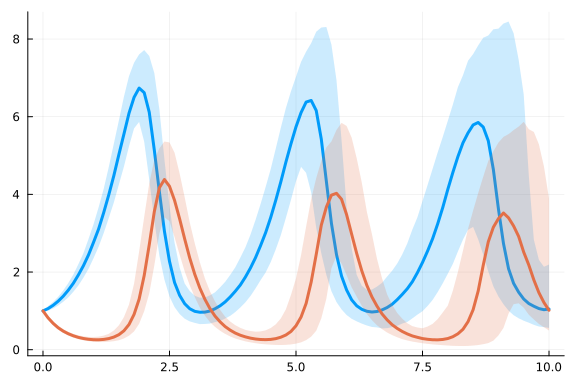
A Stochastic Differential Equation (SDE) is a differential equation that has a stochastic (noise) term in the expression of the derivatives. Here we fit a stochastic version of the Lokta-Volterra system.
We use a quasi-likelihood approach in which all trajectories of a solution are compared instead of a reduction such as mean, this increases the robustness of fitting and makes the likelihood more identifiable. We use SOSRI to solve the equation.
u0 = [1.0, 1.0]
tspan = (0.0, 10.0)
function multiplicative_noise!(du, u, p, t)
x, y = u
du[1] = p[5] * x
return du[2] = p[6] * y
end
p = [1.5, 1.0, 3.0, 1.0, 0.1, 0.1]
function lotka_volterra!(du, u, p, t)
x, y = u
α, β, γ, δ = p
du[1] = dx = α * x - β * x * y
return du[2] = dy = δ * x * y - γ * y
end
prob_sde = SDEProblem(lotka_volterra!, multiplicative_noise!, u0, tspan, p)
ensembleprob = EnsembleProblem(prob_sde)
data = solve(ensembleprob, SOSRI(); saveat=0.1, trajectories=1000)
plot(EnsembleSummary(data))
@model function fitlv_sde(data, prob)
# Prior distributions.
σ ~ InverseGamma(2, 3)
α ~ truncated(Normal(1.3, 0.5); lower=0.5, upper=2.5)
β ~ truncated(Normal(1.2, 0.25); lower=0.5, upper=2)
γ ~ truncated(Normal(3.2, 0.25); lower=2.2, upper=4)
δ ~ truncated(Normal(1.2, 0.25); lower=0.5, upper=2)
ϕ1 ~ truncated(Normal(0.12, 0.3); lower=0.05, upper=0.25)
ϕ2 ~ truncated(Normal(0.12, 0.3); lower=0.05, upper=0.25)
# Simulate stochastic Lotka-Volterra model.
p = [α, β, γ, δ, ϕ1, ϕ2]
predicted = solve(prob, SOSRI(); p=p, saveat=0.1)
# Early exit if simulation could not be computed successfully.
if predicted.retcode !== :Success
Turing.@addlogprob! -Inf
return nothing
end
# Observations.
for i in 1:length(predicted)
data[:, i] ~ MvNormal(predicted[i], σ^2 * I)
end
return nothing
end;
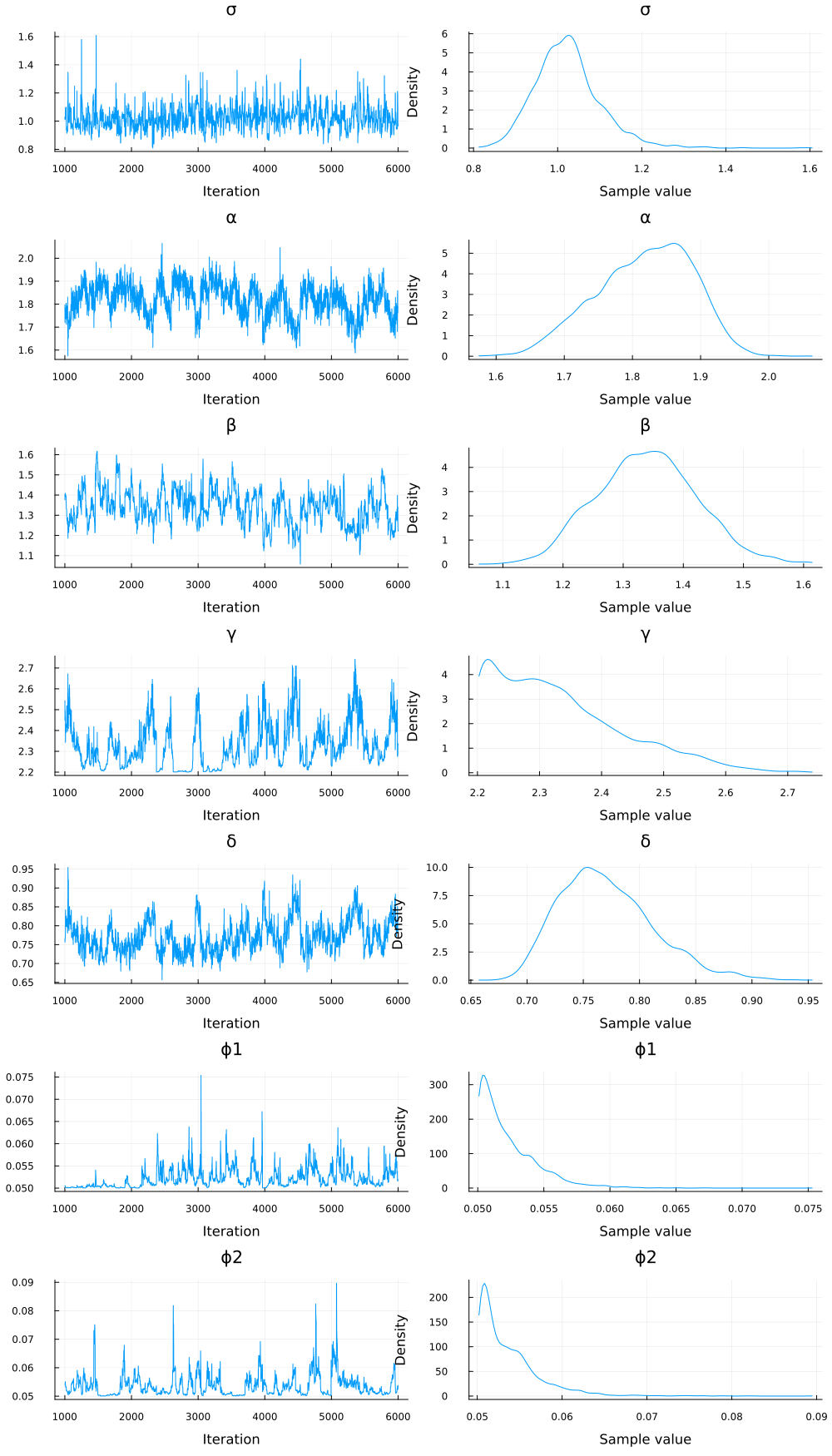
The probabilistic nature of the SDE solution makes the likelihood function noisy which poses a challenge for NUTS since the gradient is changing with every calculation.
Therefore we use NUTS with a low target acceptance rate of 0.25 and specify a set of initial parameters.
SGHMC might be a more suitable algorithm to be used here.
model_sde = fitlv_sde(odedata, prob_sde)
setadbackend(:forwarddiff)
chain_sde = sample(
model_sde,
NUTS(0.25),
5000;
init_params=[1.5, 1.3, 1.2, 2.7, 1.2, 0.12, 0.12],
progress=false,
)
plot(chain_sde)
Appendix
These tutorials are a part of the TuringTutorials repository, found at: https://github.com/TuringLang/TuringTutorials.
To locally run this tutorial, do the following commands:
using TuringTutorials
TuringTutorials.weave("10-bayesian-differential-equations", "10_bayesian-differential-equations.jmd")
Computer Information:
Julia Version 1.6.7
Commit 3b76b25b64 (2022-07-19 15:11 UTC)
Platform Info:
OS: Linux (x86_64-pc-linux-gnu)
CPU: AMD EPYC 7502 32-Core Processor
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-11.0.1 (ORCJIT, znver2)
Environment:
JULIA_CPU_THREADS = 16
BUILDKITE_PLUGIN_JULIA_CACHE_DIR = /cache/julia-buildkite-plugin
JULIA_DEPOT_PATH = /cache/julia-buildkite-plugin/depots/7aa0085e-79a4-45f3-a5bd-9743c91cf3da
Package Information:
Status `/cache/build/default-amdci4-3/julialang/turingtutorials/tutorials/10-bayesian-differential-equations/Project.toml`
[0c46a032] DifferentialEquations v7.5.0
[1ed8b502] SciMLSensitivity v7.10.0
[f3b207a7] StatsPlots v0.15.3
[fce5fe82] Turing v0.21.12
[e88e6eb3] Zygote v0.6.49
[37e2e46d] LinearAlgebra
[9a3f8284] Random
And the full manifest:
Status `/cache/build/default-amdci4-3/julialang/turingtutorials/tutorials/10-bayesian-differential-equations/Manifest.toml`
[621f4979] AbstractFFTs v1.2.1
[80f14c24] AbstractMCMC v4.1.3
[7a57a42e] AbstractPPL v0.5.2
[1520ce14] AbstractTrees v0.4.2
[79e6a3ab] Adapt v3.4.0
[0bf59076] AdvancedHMC v0.3.6
[5b7e9947] AdvancedMH v0.6.8
[576499cb] AdvancedPS v0.3.8
[b5ca4192] AdvancedVI v0.1.5
[dce04be8] ArgCheck v2.3.0
[ec485272] ArnoldiMethod v0.2.0
[7d9fca2a] Arpack v0.5.3
[4fba245c] ArrayInterface v6.0.23
[30b0a656] ArrayInterfaceCore v0.1.20
[6ba088a2] ArrayInterfaceGPUArrays v0.2.2
[015c0d05] ArrayInterfaceOffsetArrays v0.1.6
[b0d46f97] ArrayInterfaceStaticArrays v0.1.4
[dd5226c6] ArrayInterfaceStaticArraysCore v0.1.0
[a2b0951a] ArrayInterfaceTracker v0.1.1
[4c555306] ArrayLayouts v0.8.11
[13072b0f] AxisAlgorithms v1.0.1
[39de3d68] AxisArrays v0.4.6
[aae01518] BandedMatrices v0.17.7
[198e06fe] BangBang v0.3.37
[9718e550] Baselet v0.1.1
[76274a88] Bijectors v0.10.6
[d1d4a3ce] BitFlags v0.1.5
[62783981] BitTwiddlingConvenienceFunctions v0.1.4
[764a87c0] BoundaryValueDiffEq v2.9.0
[fa961155] CEnum v0.4.2
[2a0fbf3d] CPUSummary v0.1.27
[49dc2e85] Calculus v0.5.1
[7057c7e9] Cassette v0.3.10
[082447d4] ChainRules v1.44.6
[d360d2e6] ChainRulesCore v1.15.6
[9e997f8a] ChangesOfVariables v0.1.4
[fb6a15b2] CloseOpenIntervals v0.1.10
[aaaa29a8] Clustering v0.14.3
[944b1d66] CodecZlib v0.7.0
[35d6a980] ColorSchemes v3.19.0
[3da002f7] ColorTypes v0.11.4
[c3611d14] ColorVectorSpace v0.9.9
[5ae59095] Colors v0.12.8
[861a8166] Combinatorics v1.0.2
[38540f10] CommonSolve v0.2.1
[bbf7d656] CommonSubexpressions v0.3.0
[34da2185] Compat v4.2.0
[a33af91c] CompositionsBase v0.1.1
[88cd18e8] ConsoleProgressMonitor v0.1.2
[187b0558] ConstructionBase v1.4.1
[d38c429a] Contour v0.6.2
[adafc99b] CpuId v0.3.0
[a8cc5b0e] Crayons v4.1.1
[9a962f9c] DataAPI v1.12.0
[864edb3b] DataStructures v0.18.13
[e2d170a0] DataValueInterfaces v1.0.0
[e7dc6d0d] DataValues v0.4.13
[244e2a9f] DefineSingletons v0.1.2
[bcd4f6db] DelayDiffEq v5.38.0
[b429d917] DensityInterface v0.4.0
[2b5f629d] DiffEqBase v6.105.0
[459566f4] DiffEqCallbacks v2.24.1
[77a26b50] DiffEqNoiseProcess v5.13.0
[163ba53b] DiffResults v1.1.0
[b552c78f] DiffRules v1.11.1
[0c46a032] DifferentialEquations v7.5.0
[b4f34e82] Distances v0.10.7
[31c24e10] Distributions v0.25.75
[ced4e74d] DistributionsAD v0.6.43
[ffbed154] DocStringExtensions v0.8.6
[fa6b7ba4] DualNumbers v0.6.8
[366bfd00] DynamicPPL v0.20.2
[da5c29d0] EllipsisNotation v1.6.0
[cad2338a] EllipticalSliceSampling v1.0.0
[7da242da] Enzyme v0.10.6
[d4d017d3] ExponentialUtilities v1.19.0
[e2ba6199] ExprTools v0.1.8
[c87230d0] FFMPEG v0.4.1
[7a1cc6ca] FFTW v1.5.0
[7034ab61] FastBroadcast v0.2.1
[9aa1b823] FastClosures v0.3.2
[29a986be] FastLapackInterface v1.2.7
[1a297f60] FillArrays v0.13.4
[6a86dc24] FiniteDiff v2.15.0
[53c48c17] FixedPointNumbers v0.8.4
[59287772] Formatting v0.4.2
[f6369f11] ForwardDiff v0.10.32
[069b7b12] FunctionWrappers v1.1.3
[77dc65aa] FunctionWrappersWrappers v0.1.1
[d9f16b24] Functors v0.3.0
[0c68f7d7] GPUArrays v8.5.0
[46192b85] GPUArraysCore v0.1.2
[61eb1bfa] GPUCompiler v0.16.4
[28b8d3ca] GR v0.69.3
[c145ed77] GenericSchur v0.5.3
[86223c79] Graphs v1.7.4
[42e2da0e] Grisu v1.0.2
[cd3eb016] HTTP v1.4.0
[3e5b6fbb] HostCPUFeatures v0.1.8
[34004b35] HypergeometricFunctions v0.3.11
[7869d1d1] IRTools v0.4.6
[615f187c] IfElse v0.1.1
[d25df0c9] Inflate v0.1.3
[83e8ac13] IniFile v0.5.1
[22cec73e] InitialValues v0.3.1
[505f98c9] InplaceOps v0.3.0
[a98d9a8b] Interpolations v0.14.5
[8197267c] IntervalSets v0.7.3
[3587e190] InverseFunctions v0.1.8
[41ab1584] InvertedIndices v1.1.0
[92d709cd] IrrationalConstants v0.1.1
[c8e1da08] IterTools v1.4.0
[42fd0dbc] IterativeSolvers v0.9.2
[82899510] IteratorInterfaceExtensions v1.0.0
[1019f520] JLFzf v0.1.5
[692b3bcd] JLLWrappers v1.4.1
[682c06a0] JSON v0.21.3
[ccbc3e58] JumpProcesses v9.2.0
[ef3ab10e] KLU v0.3.0
[5ab0869b] KernelDensity v0.6.5
[ba0b0d4f] Krylov v0.8.4
[0b1a1467] KrylovKit v0.5.4
[929cbde3] LLVM v4.14.0
[8ac3fa9e] LRUCache v1.3.0
[b964fa9f] LaTeXStrings v1.3.0
[23fbe1c1] Latexify v0.15.17
[10f19ff3] LayoutPointers v0.1.10
[1d6d02ad] LeftChildRightSiblingTrees v0.2.0
[2d8b4e74] LevyArea v1.0.0
[6f1fad26] Libtask v0.7.0
[d3d80556] LineSearches v7.2.0
[7ed4a6bd] LinearSolve v1.26.0
[6fdf6af0] LogDensityProblems v1.0.2
[2ab3a3ac] LogExpFunctions v0.3.18
[e6f89c97] LoggingExtras v0.4.9
[bdcacae8] LoopVectorization v0.12.132
[c7f686f2] MCMCChains v5.4.0
[be115224] MCMCDiagnosticTools v0.1.4
[e80e1ace] MLJModelInterface v1.7.0
[1914dd2f] MacroTools v0.5.10
[d125e4d3] ManualMemory v0.1.8
[dbb5928d] MappedArrays v0.4.1
[739be429] MbedTLS v1.1.6
[442fdcdd] Measures v0.3.1
[128add7d] MicroCollections v0.1.2
[e1d29d7a] Missings v1.0.2
[46d2c3a1] MuladdMacro v0.2.2
[6f286f6a] MultivariateStats v0.10.0
[d41bc354] NLSolversBase v7.8.2
[2774e3e8] NLsolve v4.5.1
[872c559c] NNlib v0.8.9
[77ba4419] NaNMath v1.0.1
[86f7a689] NamedArrays v0.9.6
[c020b1a1] NaturalSort v1.0.0
[b8a86587] NearestNeighbors v0.4.12
[8913a72c] NonlinearSolve v0.3.22
[d8793406] ObjectFile v0.3.7
[510215fc] Observables v0.5.2
[6fe1bfb0] OffsetArrays v1.12.7
[4d8831e6] OpenSSL v1.2.1
[429524aa] Optim v1.7.3
[3bd65402] Optimisers v0.2.9
[bac558e1] OrderedCollections v1.4.1
[1dea7af3] OrdinaryDiffEq v6.28.0
[90014a1f] PDMats v0.11.16
[d96e819e] Parameters v0.12.3
[69de0a69] Parsers v2.4.0
[b98c9c47] Pipe v1.3.0
[ccf2f8ad] PlotThemes v3.0.0
[995b91a9] PlotUtils v1.3.1
[91a5bcdd] Plots v1.35.2
[e409e4f3] PoissonRandom v0.4.1
[f517fe37] Polyester v0.6.15
[1d0040c9] PolyesterWeave v0.1.10
[85a6dd25] PositiveFactorizations v0.2.4
[d236fae5] PreallocationTools v0.4.4
[21216c6a] Preferences v1.3.0
[08abe8d2] PrettyTables v1.3.1
[33c8b6b6] ProgressLogging v0.1.4
[92933f4c] ProgressMeter v1.7.2
[1fd47b50] QuadGK v2.5.0
[74087812] Random123 v1.6.0
[e6cf234a] RandomNumbers v1.5.3
[b3c3ace0] RangeArrays v0.3.2
[c84ed2f1] Ratios v0.4.3
[c1ae055f] RealDot v0.1.0
[3cdcf5f2] RecipesBase v1.3.0
[01d81517] RecipesPipeline v0.6.6
[731186ca] RecursiveArrayTools v2.32.0
[f2c3362d] RecursiveFactorization v0.2.12
[189a3867] Reexport v1.2.2
[05181044] RelocatableFolders v1.0.0
[ae029012] Requires v1.3.0
[ae5879a3] ResettableStacks v1.1.1
[37e2e3b7] ReverseDiff v1.14.3
[79098fc4] Rmath v0.7.0
[f2b01f46] Roots v2.0.7
[3cdde19b] SIMDDualNumbers v0.1.1
[94e857df] SIMDTypes v0.1.0
[476501e8] SLEEFPirates v0.6.36
[0bca4576] SciMLBase v1.59.4
[1ed8b502] SciMLSensitivity v7.10.0
[30f210dd] ScientificTypesBase v3.0.0
[6c6a2e73] Scratch v1.1.1
[91c51154] SentinelArrays v1.3.15
[efcf1570] Setfield v0.8.2
[992d4aef] Showoff v1.0.3
[777ac1f9] SimpleBufferStream v1.1.0
[699a6c99] SimpleTraits v0.9.4
[66db9d55] SnoopPrecompile v1.0.1
[a2af1166] SortingAlgorithms v1.0.1
[47a9eef4] SparseDiffTools v1.26.2
[276daf66] SpecialFunctions v2.1.7
[171d559e] SplittablesBase v0.1.14
[aedffcd0] Static v0.7.7
[90137ffa] StaticArrays v1.5.9
[1e83bf80] StaticArraysCore v1.4.0
[64bff920] StatisticalTraits v3.2.0
[82ae8749] StatsAPI v1.5.0
[2913bbd2] StatsBase v0.33.21
[4c63d2b9] StatsFuns v1.0.1
[f3b207a7] StatsPlots v0.15.3
[9672c7b4] SteadyStateDiffEq v1.9.0
[789caeaf] StochasticDiffEq v6.54.0
[7792a7ef] StrideArraysCore v0.3.15
[09ab397b] StructArrays v0.6.12
[53d494c1] StructIO v0.3.0
[c3572dad] Sundials v4.10.1
[ab02a1b2] TableOperations v1.2.0
[3783bdb8] TableTraits v1.0.1
[bd369af6] Tables v1.9.0
[62fd8b95] TensorCore v0.1.1
[5d786b92] TerminalLoggers v0.1.6
[8290d209] ThreadingUtilities v0.5.0
[a759f4b9] TimerOutputs v0.5.21
[9f7883ad] Tracker v0.2.22
[3bb67fe8] TranscodingStreams v0.9.9
[28d57a85] Transducers v0.4.73
[a2a6695c] TreeViews v0.3.0
[d5829a12] TriangularSolve v0.1.14
[410a4b4d] Tricks v0.1.6
[fce5fe82] Turing v0.21.12
[5c2747f8] URIs v1.4.0
[3a884ed6] UnPack v1.0.2
[1cfade01] UnicodeFun v0.4.1
[41fe7b60] Unzip v0.1.2
[3d5dd08c] VectorizationBase v0.21.51
[19fa3120] VertexSafeGraphs v0.2.0
[cc8bc4a8] Widgets v0.6.6
[efce3f68] WoodburyMatrices v0.5.5
[e88e6eb3] Zygote v0.6.49
[700de1a5] ZygoteRules v0.2.2
[68821587] Arpack_jll v3.5.0+3
[6e34b625] Bzip2_jll v1.0.8+0
[83423d85] Cairo_jll v1.16.1+1
[7cc45869] Enzyme_jll v0.0.38+0
[2e619515] Expat_jll v2.4.8+0
[b22a6f82] FFMPEG_jll v4.4.2+2
[f5851436] FFTW_jll v3.3.10+0
[a3f928ae] Fontconfig_jll v2.13.93+0
[d7e528f0] FreeType2_jll v2.10.4+0
[559328eb] FriBidi_jll v1.0.10+0
[0656b61e] GLFW_jll v3.3.8+0
[d2c73de3] GR_jll v0.69.1+0
[78b55507] Gettext_jll v0.21.0+0
[7746bdde] Glib_jll v2.74.0+1
[3b182d85] Graphite2_jll v1.3.14+0
[2e76f6c2] HarfBuzz_jll v2.8.1+1
[1d5cc7b8] IntelOpenMP_jll v2018.0.3+2
[aacddb02] JpegTurbo_jll v2.1.2+0
[c1c5ebd0] LAME_jll v3.100.1+0
[88015f11] LERC_jll v3.0.0+1
[dad2f222] LLVMExtra_jll v0.0.16+0
[dd4b983a] LZO_jll v2.10.1+0
[e9f186c6] Libffi_jll v3.2.2+1
[d4300ac3] Libgcrypt_jll v1.8.7+0
[7e76a0d4] Libglvnd_jll v1.3.0+3
[7add5ba3] Libgpg_error_jll v1.42.0+0
[94ce4f54] Libiconv_jll v1.16.1+1
[4b2f31a3] Libmount_jll v2.35.0+0
[89763e89] Libtiff_jll v4.4.0+0
[38a345b3] Libuuid_jll v2.36.0+0
[856f044c] MKL_jll v2022.1.0+0
[e7412a2a] Ogg_jll v1.3.5+1
[458c3c95] OpenSSL_jll v1.1.17+0
[efe28fd5] OpenSpecFun_jll v0.5.5+0
[91d4177d] Opus_jll v1.3.2+0
[30392449] Pixman_jll v0.40.1+0
[ea2cea3b] Qt5Base_jll v5.15.3+1
[f50d1b31] Rmath_jll v0.3.0+0
[fb77eaff] Sundials_jll v5.2.0+1
[a2964d1f] Wayland_jll v1.19.0+0
[2381bf8a] Wayland_protocols_jll v1.25.0+0
[02c8fc9c] XML2_jll v2.9.14+0
[aed1982a] XSLT_jll v1.1.34+0
[4f6342f7] Xorg_libX11_jll v1.6.9+4
[0c0b7dd1] Xorg_libXau_jll v1.0.9+4
[935fb764] Xorg_libXcursor_jll v1.2.0+4
[a3789734] Xorg_libXdmcp_jll v1.1.3+4
[1082639a] Xorg_libXext_jll v1.3.4+4
[d091e8ba] Xorg_libXfixes_jll v5.0.3+4
[a51aa0fd] Xorg_libXi_jll v1.7.10+4
[d1454406] Xorg_libXinerama_jll v1.1.4+4
[ec84b674] Xorg_libXrandr_jll v1.5.2+4
[ea2f1a96] Xorg_libXrender_jll v0.9.10+4
[14d82f49] Xorg_libpthread_stubs_jll v0.1.0+3
[c7cfdc94] Xorg_libxcb_jll v1.13.0+3
[cc61e674] Xorg_libxkbfile_jll v1.1.0+4
[12413925] Xorg_xcb_util_image_jll v0.4.0+1
[2def613f] Xorg_xcb_util_jll v0.4.0+1
[975044d2] Xorg_xcb_util_keysyms_jll v0.4.0+1
[0d47668e] Xorg_xcb_util_renderutil_jll v0.3.9+1
[c22f9ab0] Xorg_xcb_util_wm_jll v0.4.1+1
[35661453] Xorg_xkbcomp_jll v1.4.2+4
[33bec58e] Xorg_xkeyboard_config_jll v2.27.0+4
[c5fb5394] Xorg_xtrans_jll v1.4.0+3
[3161d3a3] Zstd_jll v1.5.2+0
[214eeab7] fzf_jll v0.29.0+0
[a4ae2306] libaom_jll v3.4.0+0
[0ac62f75] libass_jll v0.15.1+0
[8e850b90] libblastrampoline_jll v3.1.0+2
[f638f0a6] libfdk_aac_jll v2.0.2+0
[b53b4c65] libpng_jll v1.6.38+0
[f27f6e37] libvorbis_jll v1.3.7+1
[1270edf5] x264_jll v2021.5.5+0
[dfaa095f] x265_jll v3.5.0+0
[d8fb68d0] xkbcommon_jll v1.4.1+0
[0dad84c5] ArgTools
[56f22d72] Artifacts
[2a0f44e3] Base64
[ade2ca70] Dates
[8bb1440f] DelimitedFiles
[8ba89e20] Distributed
[f43a241f] Downloads
[9fa8497b] Future
[b77e0a4c] InteractiveUtils
[4af54fe1] LazyArtifacts
[b27032c2] LibCURL
[76f85450] LibGit2
[8f399da3] Libdl
[37e2e46d] LinearAlgebra
[56ddb016] Logging
[d6f4376e] Markdown
[a63ad114] Mmap
[ca575930] NetworkOptions
[44cfe95a] Pkg
[de0858da] Printf
[3fa0cd96] REPL
[9a3f8284] Random
[ea8e919c] SHA
[9e88b42a] Serialization
[1a1011a3] SharedArrays
[6462fe0b] Sockets
[2f01184e] SparseArrays
[10745b16] Statistics
[4607b0f0] SuiteSparse
[fa267f1f] TOML
[a4e569a6] Tar
[8dfed614] Test
[cf7118a7] UUIDs
[4ec0a83e] Unicode
[e66e0078] CompilerSupportLibraries_jll
[deac9b47] LibCURL_jll
[29816b5a] LibSSH2_jll
[c8ffd9c3] MbedTLS_jll
[14a3606d] MozillaCACerts_jll
[4536629a] OpenBLAS_jll
[05823500] OpenLibm_jll
[efcefdf7] PCRE2_jll
[bea87d4a] SuiteSparse_jll
[83775a58] Zlib_jll
[8e850ede] nghttp2_jll
[3f19e933] p7zip_jll